Tactical Auto-Evolution and Comparative Evaluation
Based on experiment_logs/test_20260305_145857
1. Architecture and Setup
The system introduces a decoupled two-stage design: Variables are controlled by testing different revolutionary sets of tactics developed by the “Agent Coach”.
1.1 Train Phase: Tactical Self-Evolution (run_evolution_experiments.py)
Models start from a "0-principle" blind test, autonomously iterating tactical principles through practical error feedback and post-match reviews by a Critic LLM.
1.2 Test Phase: Strategy Ablation (run_test_experiments.py)
2. Quantitative Results & Performance Graph
Parameters: 15 episodes/strategy, max 200 steps lagging judgement, unified Gemini 3.0 Flash driving engine.
| Strategy Tier | Tactical Features | Win Rate | Score / Total | Avg Steps |
|---|---|---|---|---|
| 🥇 Gen1 Evolved | "Pass immediately upon interception... shoot decisively" (Clear verbs) | 53.3% | 8/15 | 113.6 Steps |
| 🥈 Gen2 Evolved | "Iron-wall defense... decisive finish" (Ornate phrasing) | 40.0% | 6/15 | 132.3 Steps |
| 🥉 Manual Original | Contains rigid math thresholds: (“Shoot if x>0.85”) | 33.3% | 5/15 | 145.3 Steps |
| 📉 Empty (No Rules) | (Baseline purely relying on pre-training instincts) | 20.0% | 3/15 | 170.4 Steps |
Visualization Radar (Win Rate vs. Time Consumption)
(Blue bars denote win rate, higher is better; Red paths denote single-match execution speed, lower is crisper)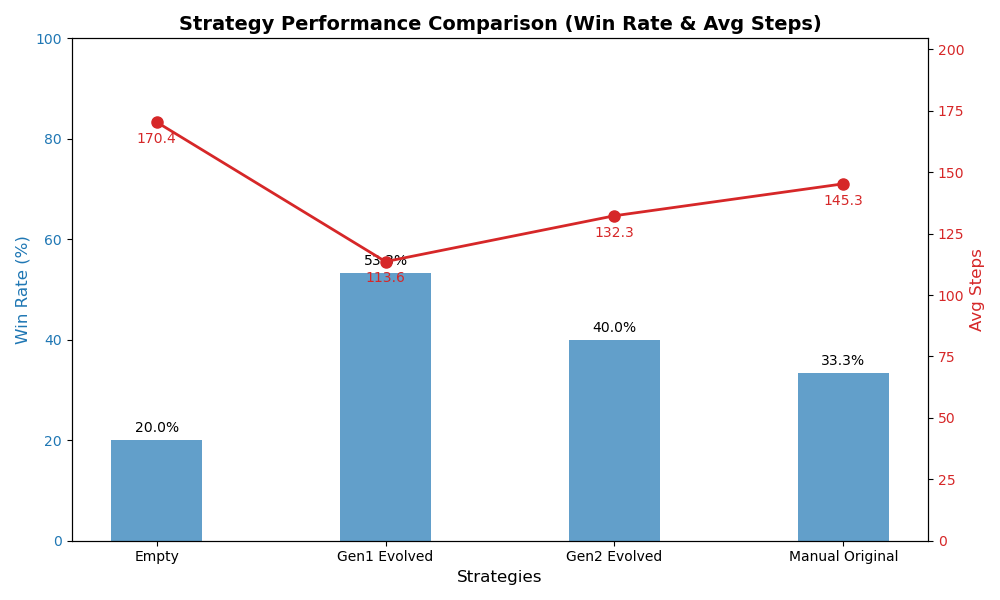
3. Core Discoveries (Findings)
- Absolute Dominance of Natural Language Prompts on Embodied Action Comparing the
Emptystrategy (20%) to theGen1strategy (53.3%): Fixing the underlying intelligence model, the sole provision of 5 high-dimensional language rules triggered an astronomical +166% surge in the agent's win rate. - LLM Self-Supervised Generation Crushes Human Priors The autonomously generated
Gen1tactics easily toppled developers' hardcodedManualguidelines. Attentional phrases (Prompts) conceived by an LLM natively align much better with the interpretation mechanism of fellow LLMs during the execution layer. - Over-iteration triggers "Semantic Misalignment" The win rate regression in
Gen2exposes a common fallacy in evaluating models (Critic): Intending to achieve perfection, it layered grandiose metaphysical terminology ("dynamic support", "iron-wall defense"). When discrete operational logic (passing/shooting) fails to translate these elevated adjectives, capability deteriorates—showcasing structural LLM hallucination and theoretical overfitting.
4. Future Roadmap
- [ ] Implement dual cross-validation of Memory + Dynamic Prompt utilizing datasets from Parts 1 & 2.
- [ ] Pioneer VLM Mulit-modal interception, passing 2D top-down rendered match snapshots to bypass spatial blocking constraints inherent in raw
(x, y)text coordinates.